
单片机与应用处理器的核心区别到底是什么呢?是核心主频的差异?还是Linux系统的支持?又或者是处理器的架构?本文将以NXP的Cortex-M系列为例做简要介绍。
一、Cortex-M的定位
处理器的体系结构定义了指令集(ISA)和基于这一体系结构下处理器的程序员模型,通俗来讲就是相同的ARM体系结构下的应用软件是兼容的。从ARMv1到ARMv8,每一次体系结构的修改都会添加实用技术。
在ARMv7版本中,内核架构首次从单一款式变成3种款式。Cortex-M系列属于ARMv7结构下的一个款式:款式M。款式M包含的处理器有Cortex-M0、Cortex-M1、Cortex-M3、Cortex-M4以及Cortex-M7,以上处理器常被用于低成本、低功耗、高可靠的嵌入式实时系统中。它们既可以用于“裸片”开发又能运行实时操作系统,比如us/os-ll、VxWorks以及Aworks(致远电子开发)等。
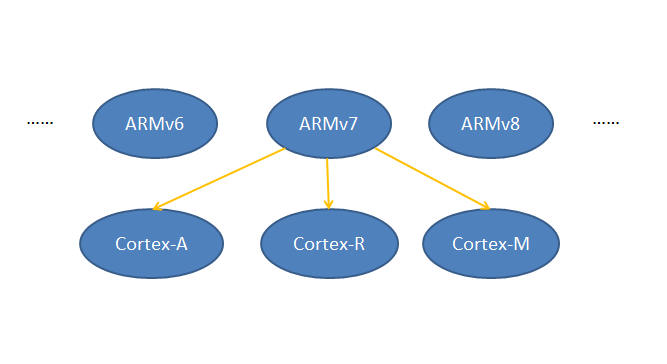
图1 ARMv7下的Cortex系列
● 款式A:高性能的处理器级平台,性能比肩计算机。
● 款式R:定位应用于高端嵌入式系统,高可靠及高时效性。
● 款式M:用于深度嵌入、定制的嵌入式系统。
值得注意的是,Cortex-M下的处理器没有内存管理单元MMU。
二、内存管理单元MMU
内存管理单元简称MMU,它负责虚拟地址到物理地址的映射,并提供硬件机制的内存访问权限检查。在多用户、多进程的操作系统中,MMU使得各个用户进程都有独立的地址空间。

图2 MMU的地位
任何微控制器都存在一个程序能够产生的地址集和,被称为虚拟地址范围。以32为机为例,虚拟地址范围为0~0xFFFFFFFF (4G)。当该控制器寻址一个256M的内存时,它的可用地址范围被限定为0x00000000~0x0FFFFFFF(256M)。在没有MMU的控制器中,虚拟地址被直接发送到内存总线上,以读写该地址下的物理存储器。在拥有MMU的控制器中,虚拟地址首先被发送到MMU中,被映射为物理地址后再发送到内存总线上。

图3 内存管理机制
注:上图仅简单反映内存管理的映射机制,权限映射、TLB快表、页表等概念不做深入讨论。
虚拟内存管理最主要的作用是让每个进程有独立的地址空间。不同进程中的同一个虚拟地址被MMU映射到不同的物理地址,并且在某一个进程中访问任何地址都不可能访问到另外一个进程的数据,这样使得任何一个进程由于执行错误指令或恶意代码导致的非法内存访问都不会意外改写其它进程的数据,不会影响其它进程的运行,从而保证整个系统的稳定性。另一方面,每个进程都认为自己独占整个虚拟地址空间,这样链接器和加载器的实现会比较容易,不必考虑各进程的地址范围是否冲突。
 0
0











